
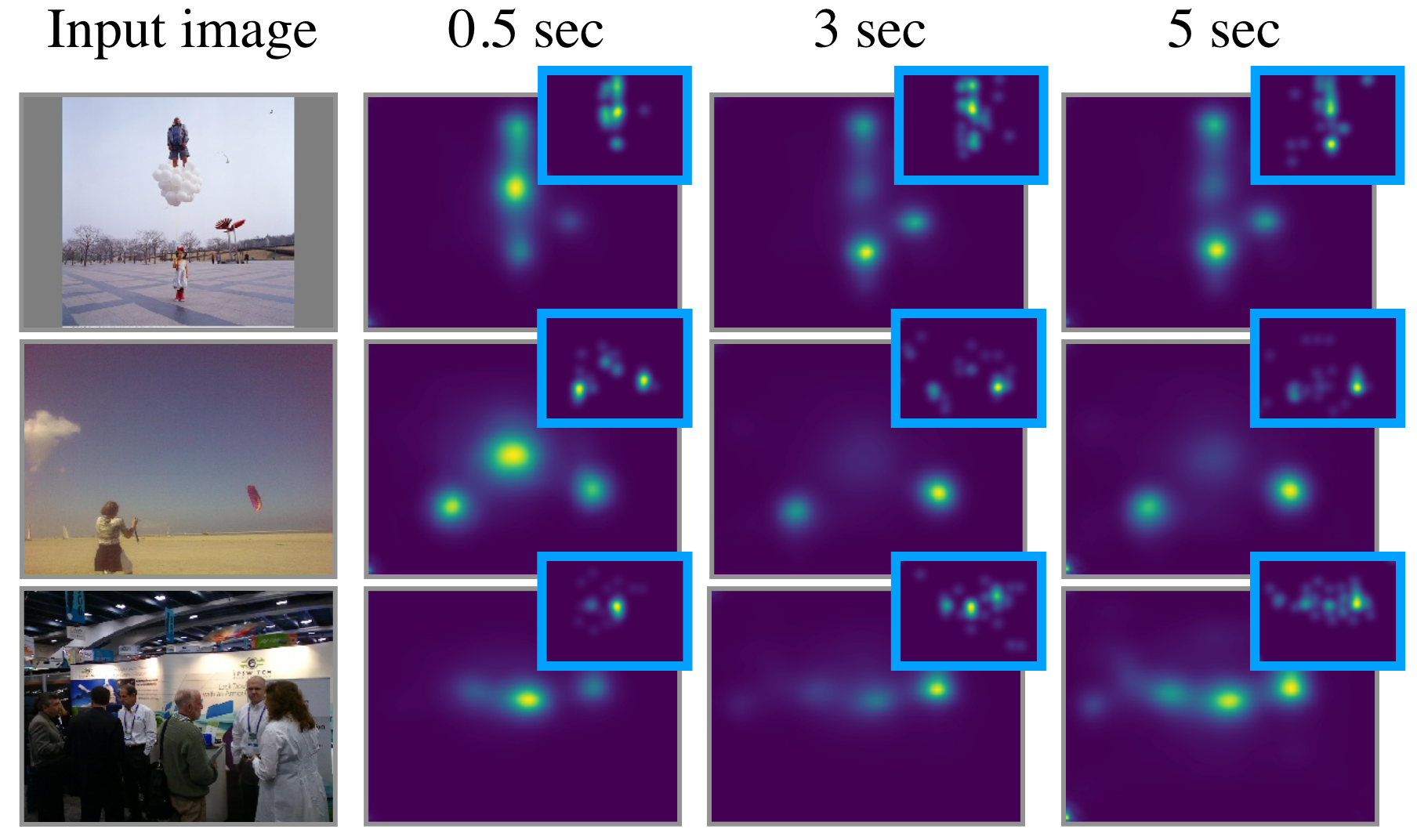
Example multiduration predictions from our Multi-Duration Saliency Excited Model (MD-SEM).
Dataset
CodeCharts1K is the first multi-duration saliency dataset. It contains 1000 images from a variety of datasets, with saliency heatmaps corresponding to 0.5, 3, and 5 seconds of viewing. We used the CodeCharts interface to crowdsource our multiduration data. The CodeCharts1K dataset and the CodeCharts interface are made available.

Example multi-duration saliency heatmaps from the CodeCharts1K dataset, featuring images taken from a variety of datasets.
Code/Models
We provide code for training and evaluating our model. Our pretrained model weights are available for download.

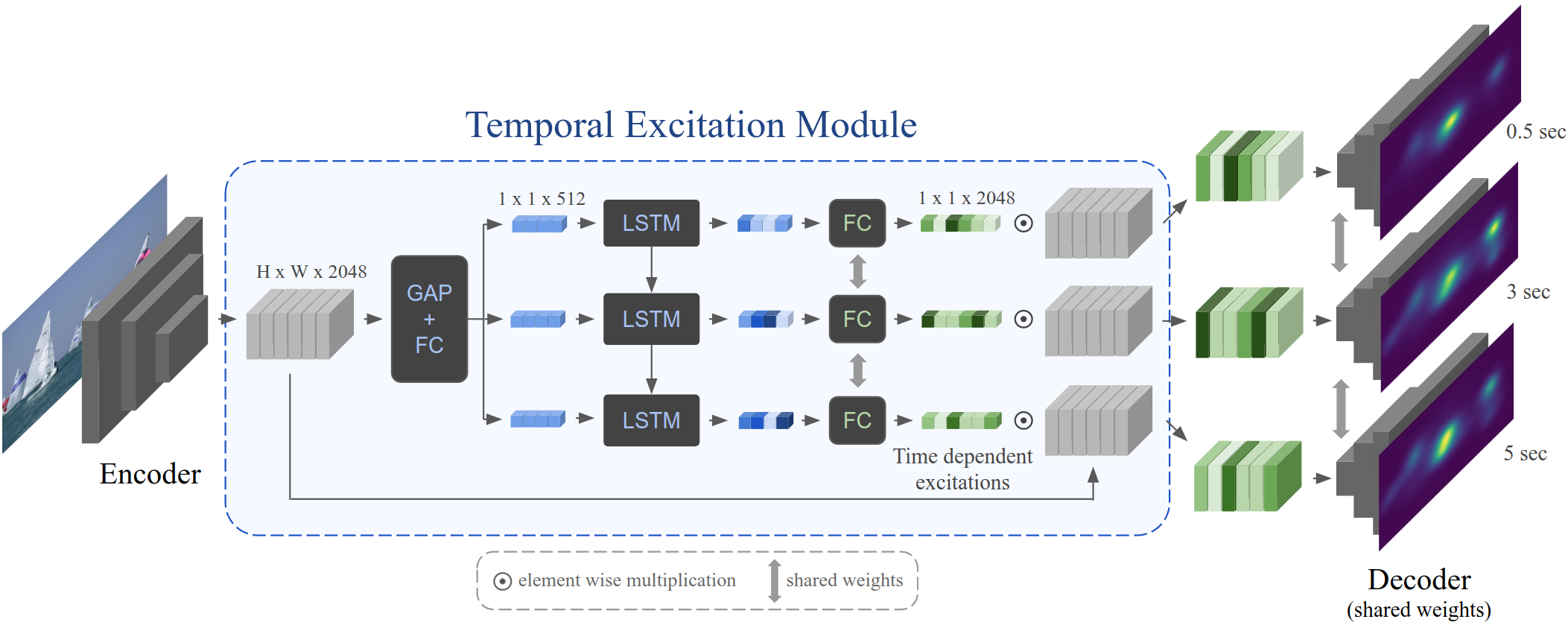
Architecture for our Multi-Duration Saliency Excited Model (MD-SEM).
Applications
Multiduration saliency can add extra temporal context to saliency-based applications like cropping, compression/rendering, and captioning. We publish code to demo these applications based on our multi-duration predictions.
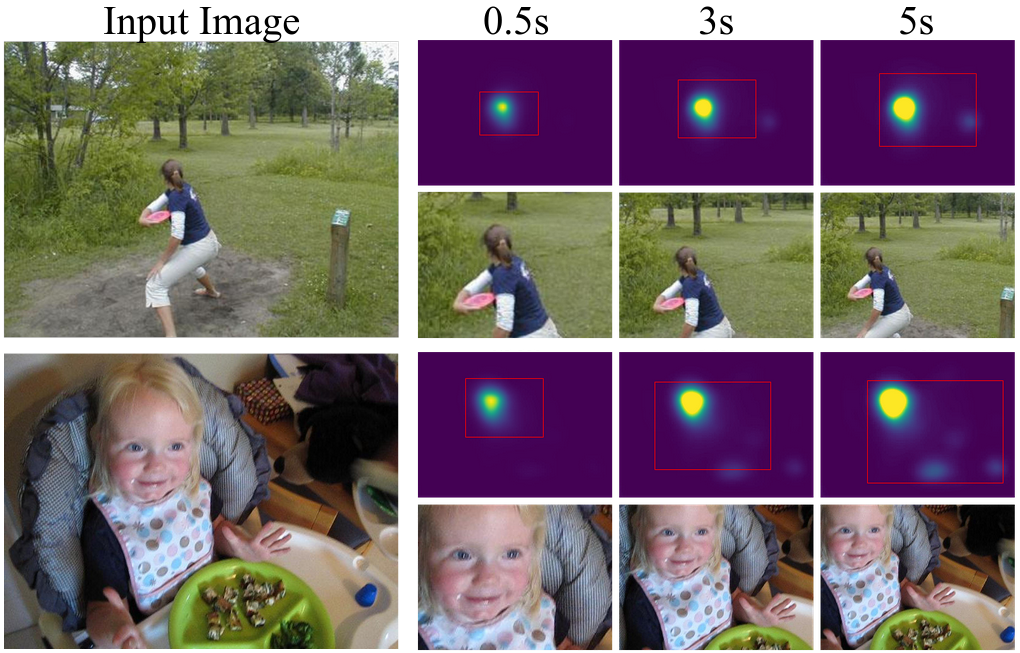
Automatic crops based on multi-duration saliency predictions produced by our model.
Publicity
- 06/2020: We presented our paper at CVPR 2020 [teaser video] [poster]
- 06/2020: We presented our paper as a talk at VSS 2020 [talk recording]
- 06/2020: Our work was featured in an MIT News article
- 12/2019: We presented our work at the SVRHM workshop at NeurIPS 2019
Authors
-
Camilo Fosco*

camilolu@mit.edu
-
Anelise Newman*

apnewman@mit.edu
-
Pat Sukhum

psukhum@g.harvard.edu
-
Yun Bin Zhang

ybzhang@g.harvard.edu
-
Nanxuan Zhao

nanxuanzhao@gmail.com
-
Aude Oliva

oliva@mit.edu
-
Zoya Bylinskii

bylinski@adobe.com